Voice Component Modeling with Behringer Deepmind
Advanced Modulation to Achieve Analog VCO Type of Tuning Offsets
 The Behringer Deepmind is capable of doing some advanced voice modeling. While it doesn't have virtual voice allocation amounts, or granular voice-by-voice controls for making specific adjustments, it is still quite capable of achieving results similar to the Prophet Rev2. One of the interesting things we noted when experimenting with Deepmind is that there are offsets built into the Note Number modulator and Voice Number modulator sources that give you bi-directional postive/negative values, without providing additional offsets elsewhere in oscillator tuning settings.
The Behringer Deepmind is capable of doing some advanced voice modeling. While it doesn't have virtual voice allocation amounts, or granular voice-by-voice controls for making specific adjustments, it is still quite capable of achieving results similar to the Prophet Rev2. One of the interesting things we noted when experimenting with Deepmind is that there are offsets built into the Note Number modulator and Voice Number modulator sources that give you bi-directional postive/negative values, without providing additional offsets elsewhere in oscillator tuning settings.
1. DEEPMIND Note Number Modulation:
The Note Number modulator has a "built in offset" in the calculation, where C2 is the 0-point, rather than starting at the first Midi-Note.
If you have positive Note Number Modulation, everything above C2 will progressively get higher output values, and all notes below C2 will get lower (negative) output values.
Conversely, if you set the amount in negative territory, then output will become progressively more negative going up from C2, but get progressively positive values down below C2.
Note Number Output Scale
Note Number Souce with Amount of 127 = ~ +1 output value per consecutive key press, with 0-point starting at C2.
Approximately +48 output at high C6 on 61-key keyboard
Approximately -12 output at bottom C1 on 61-key keyboard.
 2. DEEPMIND Voice Number Modulation:
2. DEEPMIND Voice Number Modulation:
Voice Number modulator also has a "built in offset". The center point is in between Voices 6 and 7 on the Deepmind 12. Voice number six/siven will be the approximate 0-point where little modulation output is sent (only small output relative to the value set high values set for amount)
If you use Voice Number Source, with Amount of 127 in the Mod Matrix, can expect the following approximate output values:
Voice 1: -127
Voice 2: -104
Voice 3: -81
Voice 4: -58
Voice 5: -35
Voice 6: -12
Voice 7: +12
Voice 8: +35
Voice 9: +58
Voice 10: +81
Voice 11: +104
Voice 12: +127
Conversely, with a negative amount entered, the opposite is true, Voice 1 will start at the negative number and swing through other voices getting more positive.
The Cat on Keyboard Trick
The Deepmind, in its default state, cycles through voices in a consecutive manner, which is not ideal. It ends up giving you similar voice number offsets for consecutive key strikes, rather than a more random selection of values which is preferred. There is a workaround for this. After turning on your Deepmind, go to a patch that is polyphonic and uses all 12 voices, and just lean your whole forearm onto the keyboard a few times, mashing dozens of keys at a time. This will randomize the voice number selection for each key your hit, giving you better results in voice modeling.
3. Settings for Voice Component Modeling
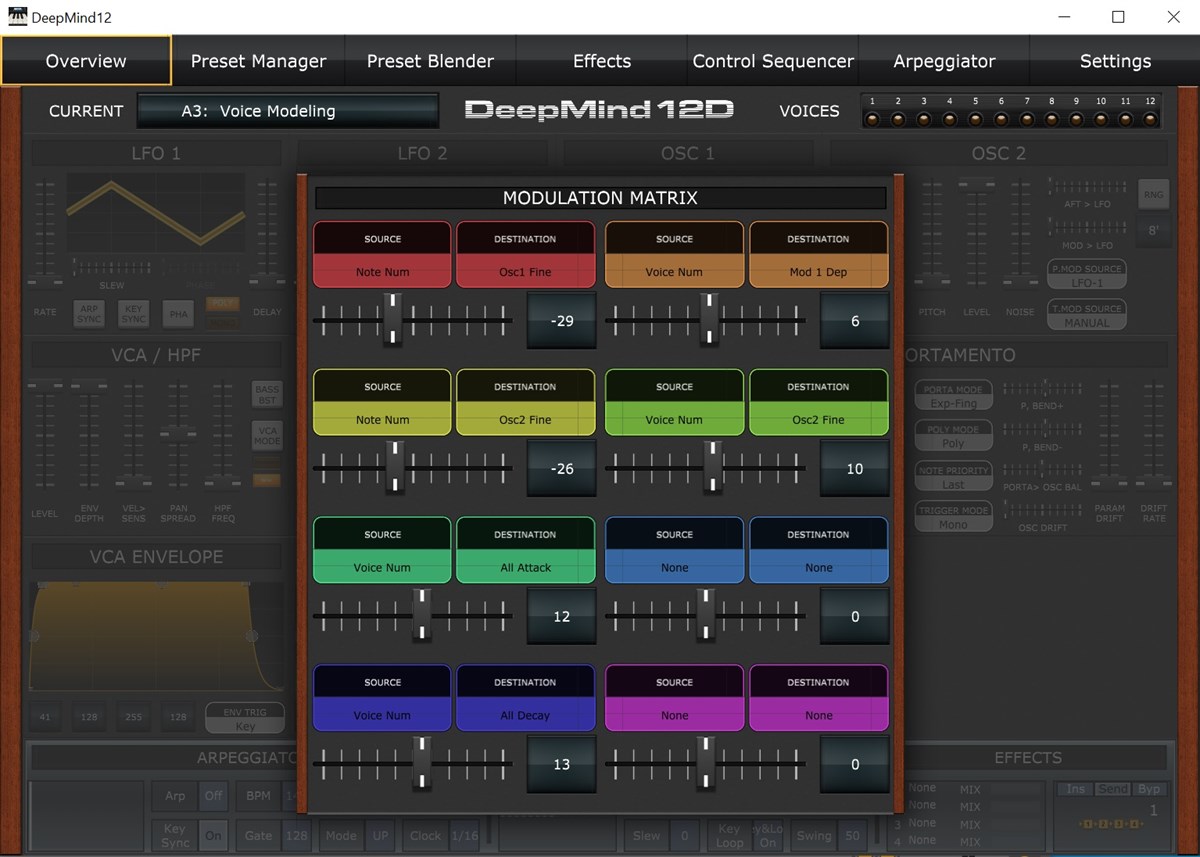
 Below are Mod Matrix settings to acheive voice-by-voice tuning character that is almost identical to the Prophet Rev2 VCM settings, and the classic synths that were tested and measured (OBX, OBXA, SEM 4-Voice, Jupiter 4, Jupiter 8, CS-80, etc..) The most common measured characteristic was that each voice (and each oscillator within the voices) tend to get either more flat or more sharp, relative to their target pitch, as you progress up the keyboard span. This is all relative to the master tuning. This type of behavior happens on a majority of the VCO Poly Synths tested, and is unique per voice and per oscillator, with small offsets and variance to the amounts. The below mod matrix settings will give the Deepmind a poly voice tuning character that is pretty much identical to the Oberheim OBX and OBXAs that were tested, with intonation and offsets on a per voice / per oscillator basis.
Below are Mod Matrix settings to acheive voice-by-voice tuning character that is almost identical to the Prophet Rev2 VCM settings, and the classic synths that were tested and measured (OBX, OBXA, SEM 4-Voice, Jupiter 4, Jupiter 8, CS-80, etc..) The most common measured characteristic was that each voice (and each oscillator within the voices) tend to get either more flat or more sharp, relative to their target pitch, as you progress up the keyboard span. This is all relative to the master tuning. This type of behavior happens on a majority of the VCO Poly Synths tested, and is unique per voice and per oscillator, with small offsets and variance to the amounts. The below mod matrix settings will give the Deepmind a poly voice tuning character that is pretty much identical to the Oberheim OBX and OBXAs that were tested, with intonation and offsets on a per voice / per oscillator basis.
a: Mod Slot 1:
Source: Note Number
Destination: Osc1 Fine Tuning
Amount: -29
Note: This sets the general intonation tuning for Osc1, getting relatively more flat going up the keyboard
b. Mod Slot 2:
Source: Voice Number
Destination: Mod 1 Depth
Amount: 6
Note: This makes slight adjustments to the Mod Slot 1 Intonation offset, on a per-voice basis
c: Mod Slot 3:
Source: Note Number
Destination: Osc 2 Fine Tuning
Amount: -26
Note: This gives Osc2 the same sort of intonation going up the keyboard, slightly offset from the Osc1 amount
d: Mod Slot 4:
Source: Voice Number
Destination: Osc 2 Fine Tuning
Amount: 10
Note: Here, we're routing Voice Num directly to Osc2 Fine Tune.. This gives the majority of the per voice phasing offset difference between the two oscillators
Note: We could add a modulation like Mod Slot 2 for Osc2s Intonation variance, but I don't think its needed, since the other modulations combined cover the majority of the modeling to mimic an OBX/OBXA tuning character.
e: Mod Slot 5/6/etc...
Source: Voice Number
Destination: Attack, Decay, other Characteristics
Amount: 2-15 (for attack/decay depending on patch type)
Note: Varying the attack speed of envelopes on a voice-by-voice basis can make envelopes sound much more organic, as the cutoff sweeps will be slightly varied per voice / per note. This type of variance is present at varying levels on older VCO synths. Its especially noticable with sounds like the "Tom Sawyer" type of filter sweep with resonance. Modulating the attack speed per voice has a downstream effect on decay as well, since they are temporally connected together.
4. DEEPMIND Pan Spread:
The Pan Spread route the above Voice Number to a Fixed Left/Right pan position. If you enter +127 as the Pan Spread amount, then voice one will be panned hard left, and voice twelve will be panned hard right. Voices six and seven will be near center panning.